前言
最近想用自己之前写的脚本看看市场行情,结果发现代码竟然跑不通了!
仔细一查,发现BOSS直聘的岗位搜索结果页做了三个改动:
- 反爬检测:打开开发者工具就进入无限循环,或者整个网页闪退关闭
- 分页机制取消:以前通过 page 参数翻页的方式失效了。
- 薪资数据加密:列表页的薪资数字变成了乱码,用字体加密的方式防止直接采集。
不过我发现虽然搜索结果页加密了,但每个岗位的详情页里的薪资,还是明文的!
基于这个发现,我的主要调整思路是:
- 临时禁用JavaScript,让页面以纯静态形式加载。
- 适配新的页面加载方式,改为滚动加载职位信息。
- 无视搜索结果页的薪资加密,直接解析详情页。
缺点:由于是通过自动化的方式采集数据,效率比较一般(300个岗位详情20分钟左右采集完)
优点:稳定,不容易触发反爬,试了五个关键词采集,也就是1500个详情页解析,个人的话应该够用
我把脚本整理了一下,发出来供有类似需求的朋友参考。欢迎交流~
1.cookie处理
脚本打开浏览器后,打开登录界面,扫码登录,等待脚本保存 cookie
def get_cookie(self, url='https://www.zhipin.com', timeout=30):
"""获取Cookie(手动登录)"""
logger.info("请打开登录窗口,扫码登录您的个人账号...")
self.page.get(url)
time.sleep(timeout) # 等待手动登录
cookies = self.page.cookies()
self.file_manager.save_json(cookies, self.config.cookie_file)
logger.info(f"Cookie已保存到 {self.config.cookie_file}")
def load_cookie(self) -> bool:
"""加载Cookie"""
if not os.path.exists(self.config.cookie_file):
logger.warning(f"Cookie文件不存在: {self.config.cookie_file}")
return False
logger.info("开始加载Cookie")
self.page.get("https://www.zhipin.com")
time.sleep(2)
cookies = self.file_manager.load_json(self.config.cookie_file)
for cookie in cookies:
self.page.set.cookies(cookie)
self.page.refresh()
time.sleep(2)
logger.info("Cookie加载完成")
# 保存首页HTML
if self.config.save_html_debug:
self.file_manager.save_html(self.page.html, "01_首页_加载Cookie后")
return True
2.首页处理
2.1 前置步骤(绕过反爬检测,仅调试时勾选!)
注:正常访问网站时发生异常(比如一直在空白页加载),可能是这个禁用js的选项没有取消勾选,取消勾选后再刷新网站即可正常访问
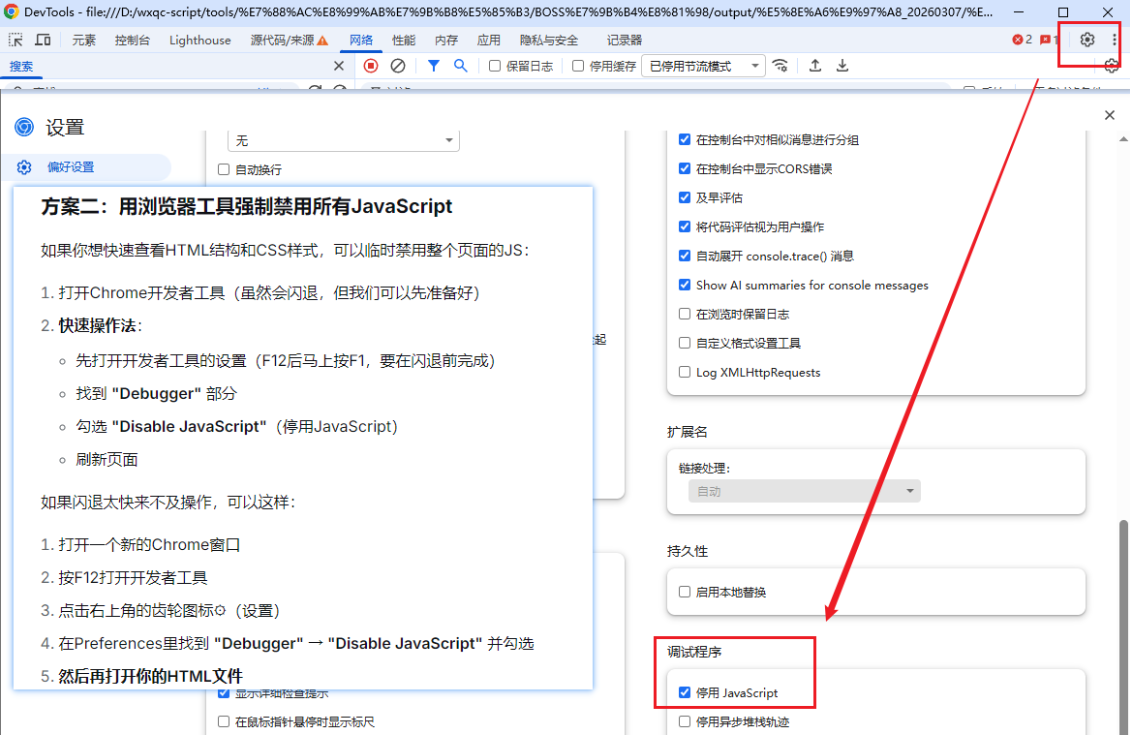
由于目标网站设置了严格的反爬虫机制,直接按 F12 进入开发者工具,网站会闪退。我们可以通过临时禁用浏览器JavaScript来绕过大部分检测,让页面以纯静态形式加载,这个模式下我们可以随意定位元素。
操作步骤:
- 打开浏览器,按
F12进入开发者工具 - 点击右上角的 齿轮图标 ⚙ 进入设置
- 向下找到 "Debugger"(调试器) 部分
- 勾选 "Disable JavaScript"(禁用 JavaScript)
图示:
2.2 职位搜索
如图所示,通过选择器选择输入框,可以得到整个输入框的元素
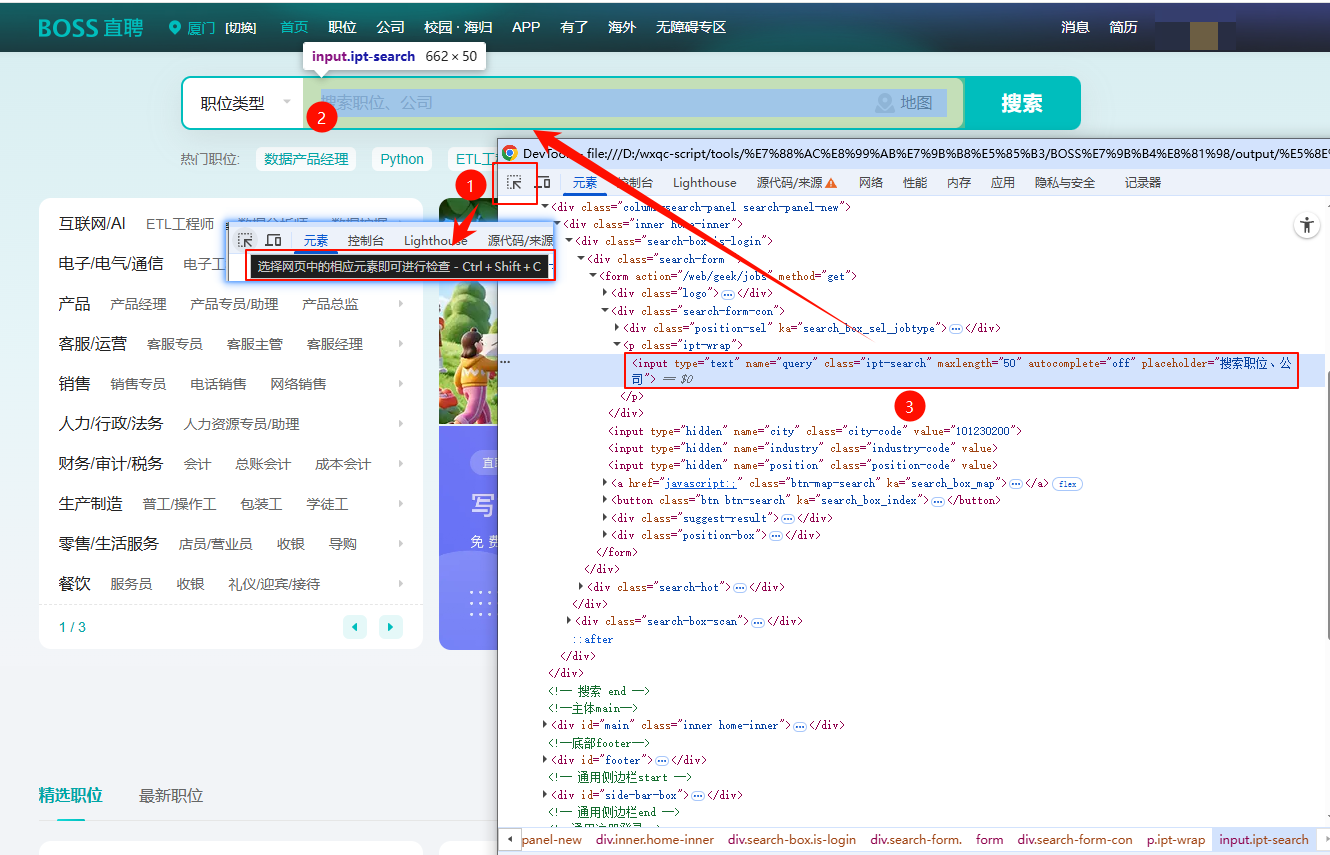
由此可以得到首页输入岗位名称并搜索的代码:访问首页,等待搜索框元素,清空搜索框,输入关键词,回车
回车后即可进入搜索结果页面
# 访问首页
logger.info("正在访问BOSS直聘首页...")
self.page.get("https://www.zhipin.com/")
# 等待搜索框出现(匹配class或placeholder符合的input元素)
self.page.wait.ele_displayed('xpath://input[@class="ipt-search" or @placeholder="搜索职位、公司"]', timeout=10)
# 输入搜索词
logger.info("正在输入搜索关键词...")
# 获取搜索框元素
search_input = self.page.ele('xpath://input[@class="ipt-search" or @placeholder="搜索职位、公司"]', timeout=10)
self.page.scroll.to_see(search_input) # 滚动到搜索框
search_input.clear() # 清空搜索框
time.sleep(0.5)
search_input.input(self.config.job_name) # 输入搜索词
time.sleep(0.5)
search_input.input('\n') # 回车确认
# 等待搜索结果
time.sleep(1) # 等待页面刷新
new_url = re.sub(r'city=\d+', f'city={self.config.city_code}', self.page.url) if self.config.city_code else self.page.url # 替换城市代码,通过get_city_code方法赋值给self.config.city_code,就可以获取目标城市的搜索请求URL
logger.info(f"正在访问搜索结果页: {new_url}")
self.page.get(new_url)
logger.info(f"等待 {self.config.search_wait_time} 秒,请开始你的条件筛选(例如:学历,工作经验)")
time.sleep(self.config.search_wait_time)
logger.info(f"搜索结果页URL未发生变化") if self.page.url == new_url else logger.info(f"搜索结果页URL发生变化: {self.page.url}")
2.3 拓展-高级搜索
示例,我需要输入城市即可返回对应的城市代码
def get_city_code(self, city_name: str) -> Optional[str]:
"""根据城市名称获取城市代码"""
try:
logger.debug(f"正在从Boss直聘API获取城市 [{city_name}] 的代码...")
response = requests.get("https://www.zhipin.com/wapi/zpCommon/data/city.json")
if response.status_code != 200:
logger.error(f"请求城市数据失败,状态码: {response.status_code}")
return None
data = response.json()
# 遍历查找城市
for province in data['zpData']['cityList']:
for city in province['subLevelModelList']:
if city['name'] == city_name:
city_code = city['code']
self.cache[city_name] = city_code
return city_code
return None
except Exception as e:
logger.error(f"获取城市代码失败: {e}")
return None
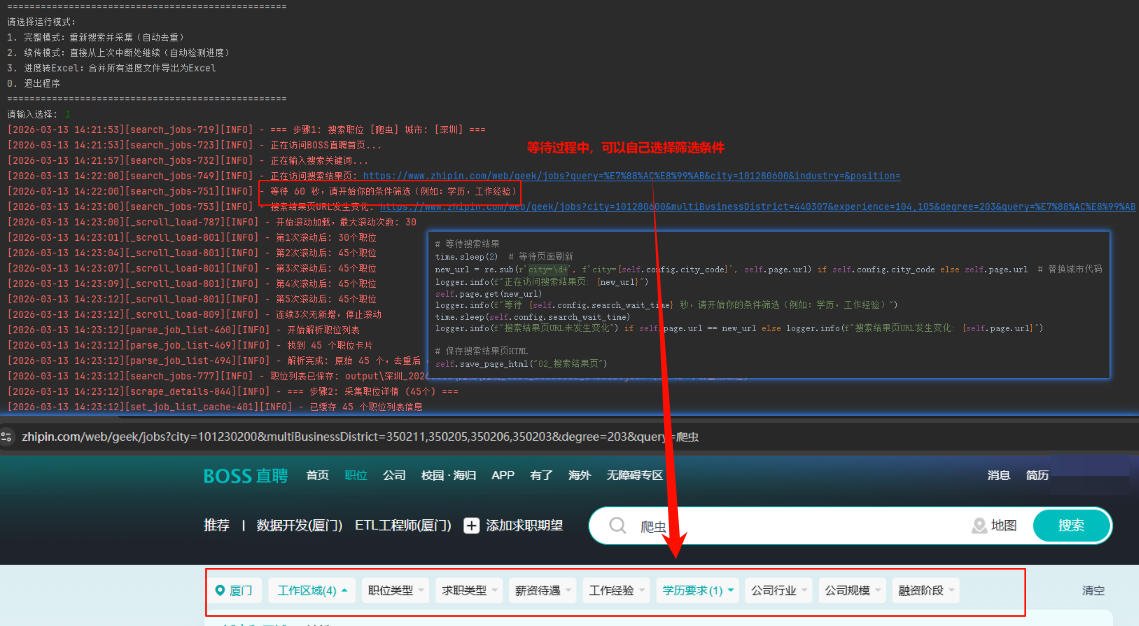
由于筛选条件有点多,我这边只做了一个自定义,其他筛选就通过search_wait_time等待的时候,在网页上直接筛选,如图所示
如果需要构造高级搜索条件,可以参考

def fetch_job_conditions(output_file):
"""获取筛选条件的相关数据,并保存为 JSON 文件"""
data = requests.get("https://www.zhipin.com/wapi/zpgeek/search/job/condition.json", verify=False).json()
# 构建新的字典格式
output_data = {
"experience": [],
"degree": [],
"payType": [],
"salary": [],
"stage": [],
"scale": [],
"partTime": [],
"jobType": []
}
# 提取工作经验数据
for experience in data['zpData']['experienceList']:
output_data["experience"].append({
"code": experience["code"],
"name": experience["name"]
})
# 提取学历数据
for degree in data['zpData']['degreeList']:
output_data["degree"].append({
"code": degree["code"],
"name": degree["name"]
})
# 提取薪资类型数据
for pay in data['zpData']['payTypeList']:
output_data["payType"].append({
"code": pay["code"],
"name": pay["name"]
})
# 提取薪资范围数据
for salary in data['zpData']['salaryList']:
output_data["salary"].append({
"code": salary["code"],
"name": salary["name"]
})
# 提取融资阶段数据
for stage in data['zpData']['stageList']:
output_data["stage"].append({
"code": stage["code"],
"name": stage["name"]
})
# 提取公司规模数据
for scale in data['zpData']['scaleList']:
output_data["scale"].append({
"code": scale["code"],
"name": scale["name"]
})
# 提取兼职类型数据
for part_time in data['zpData']['partTimeList']:
output_data["partTime"].append({
"code": part_time["code"],
"name": part_time["name"]
})
# 提取职位类型数据
for job_type in data['zpData']['jobTypeList']:
output_data["jobType"].append({
"code": job_type["code"],
"name": job_type["name"]
})
# 保存为 JSON 文件
with open(output_file, "w", encoding="utf-8") as f:
json.dump(output_data, f, ensure_ascii=False, indent=4)
print(f"筛选条件数据已保存到 {output_file} 文件中。")
3.搜索结果页处理
同 2.1 步骤,先临时禁用浏览器JavaScript防止反爬检测,方便我们使用开发者工具定位元素
如图所示,通过选择器选择职位任意参数,得到右边的信息
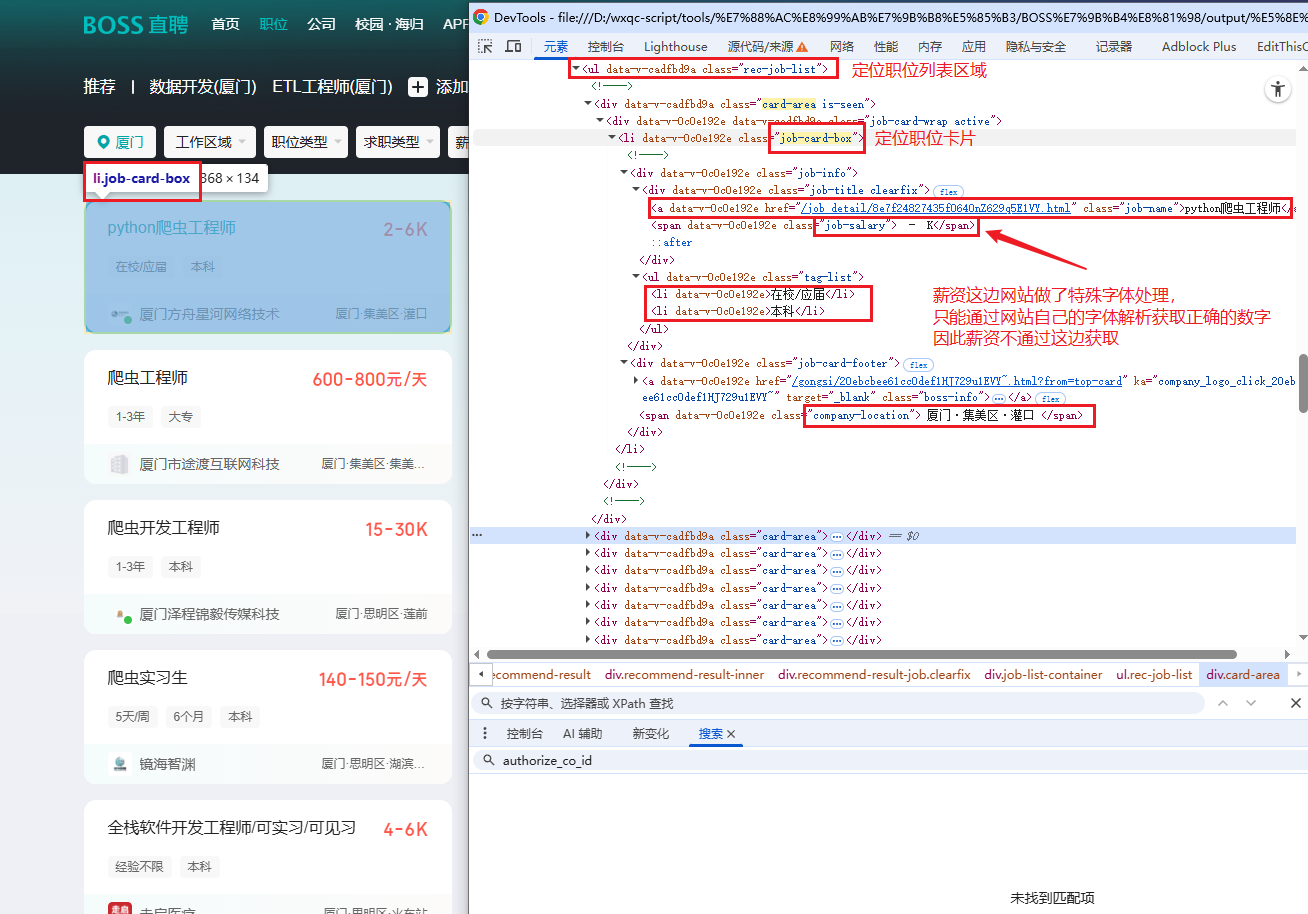
3.1 滚动加载职位信息
注:平台限制,最多加载300个岗位信息,如果想搜索匹配的信息,建议先做条件筛选再进行采集
def _scroll_load(self):
"""滚动加载更多职位"""
logger.info(f"开始滚动加载,最大滚动次数: {self.config.search_max_scrolls}")
last_count = 0
no_increase = 0
for i in range(self.config.search_max_scrolls):
self.page.scroll.to_bottom() # 滚动到底部,触发懒加载
time.sleep(1.5) # 等待加载
# 定位职位列表容器:匹配class包含"rec-job-list"的ul元素
job_list = self.page.ele('xpath://ul[contains(@class, "rec-job-list")]', timeout=5)
if job_list:
# 获取当前页职位数量:在job_list内部搜索所有class包含"job-card-box"的li元素,eles() 返回多个元素(列表)
current = len(job_list.eles('xpath:.//li[contains(@class, "job-card-box")]'))
logger.info(f"第{i + 1}次滚动后: {current}个职位")
if current > last_count:
no_increase = 0
last_count = current
else:
no_increase += 1
if no_increase >= 3:
logger.info("连续3次无新增,停止滚动")
break
time.sleep(1)
3.2 搜索结果页解析脚本
def _parse_job_card(self, card, index: int) -> Optional[Dict]:
"""解析单个职位卡片"""
job = {
'序号': index,
'职位名称': '',
'薪资': '',
'公司': '',
'工作地点': '',
'经验要求': '',
'学历要求': '',
'职位详情链接': '',
'公司详情链接': '',
'职位唯一ID': ''
}
# 职位名称和链接
name_elem = card.ele('xpath:.//a[contains(@class, "job-name")]')
if name_elem:
job['职位名称'] = self.clean_text(name_elem.text)
href = name_elem.attr('href')
if href:
job['职位详情链接'] = 'https://www.zhipin.com' + href if not href.startswith('http') else href
# # 薪资(该页面的薪资是加密的,直接跳过)
# salary_elem = card.ele('xpath:.//span[contains(@class, "job-salary")]')
# job['薪资'] = self.clean_text(salary_elem.text)
# 公司
company_elem = card.ele('xpath:.//span[contains(@class, "boss-name")]')
if company_elem:
job['公司'] = self.clean_text(company_elem.text)
# 地点
loc_elem = card.ele('xpath:.//span[contains(@class, "company-location")]')
if loc_elem:
job['工作地点'] = self.clean_text(loc_elem.text)
# 经验学历标签
tag_list = card.ele('xpath:.//ul[contains(@class, "tag-list")]')
if tag_list:
tags = [tag.text for tag in tag_list.eles('tag:li')] # 提取所有li元素的文本
if len(tags) > 0:
job['经验要求'] = tags[0]
if len(tags) > 1:
job['学历要求'] = tags[1]
# 公司链接
company_link_elem = card.ele('xpath:.//a[contains(@class, "boss-info")]')
if company_link_elem:
href = company_link_elem.attr('href')
if href:
job['公司详情链接'] = 'https://www.zhipin.com' + href
return job if job['职位名称'] else None
4.详情页处理
同 2.1 步骤,先临时禁用浏览器JavaScript防止反爬检测,方便我们使用开发者工具定位元素
如图所示,通过选择器选择职位任意参数,得到右边的信息
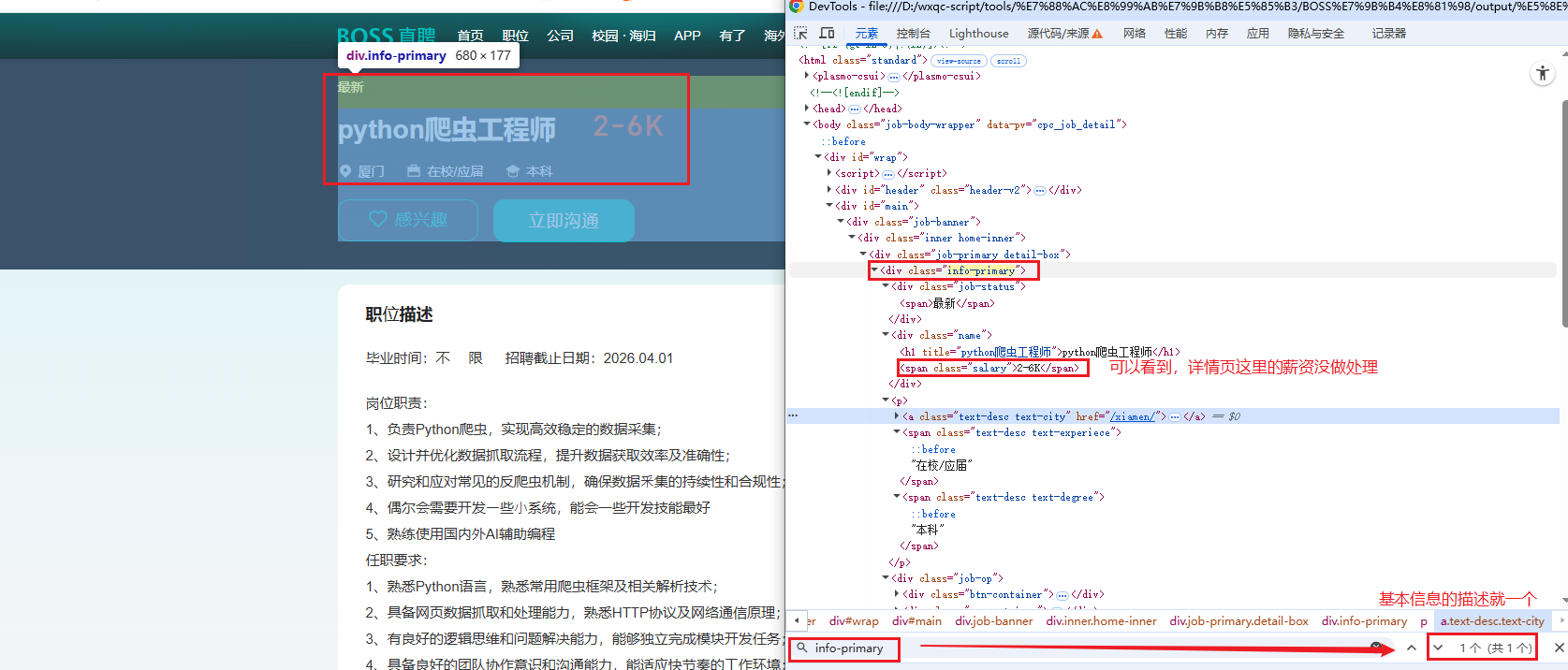
4.1详情页解析脚本
def parse_job_detail(self, page: ChromiumPage, index: int, job_url: str = '') -> Dict:
"""解析职位详情页,并与列表数据合并"""
job_id = self.extract_job_id(job_url)
# 初始化基础数据
job = {
'序号': index,
'数据采集时间': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'职位状态': '',
'职位标题': '',
'薪资': '',
'工作城市': '',
'工作区域': '',
'工作地点': '',
'经验要求': '',
'学历要求': '',
'岗位标签': '',
'职位描述': '',
'职位详情链接': job_url,
'职位唯一ID': job_id,
'公司名称': '',
'融资情况': '',
'公司规模': '',
'所属行业': '',
'公司详情链接': '',
'招聘负责人': '',
'活跃状态': '',
'招聘者职位': ''
}
# 从缓存中合并列表数据
if job_id and job_id in self.job_list_cache:
list_data = self.job_list_cache[job_id]
job['职位标题'] = list_data.get('职位名称', '')
job['薪资'] = list_data.get('薪资', '')
job['工作区域'] = list_data.get('工作地点', '').split('·')[1] if '·' in list_data.get('工作地点', '') else ''
job['工作地点'] = list_data.get('工作地点', '') if '·' in list_data.get('工作地点', '') else ''
job['公司名称'] = list_data.get('公司', '')
job['公司详情链接'] = list_data.get('公司详情链接', '')
if list_data.get('经验要求'):
job['经验要求'] = list_data.get('经验要求', '')
if list_data.get('学历要求'):
job['学历要求'] = list_data.get('学历要求', '')
try:
# 基本信息区域
info_primary = page.ele('xpath://div[@class="info-primary"]', timeout=5)
if info_primary:
job['职位状态'] = self._get_text(info_primary, 'xpath:.//div[contains(@class, "job-status")]')
job['职位标题'] = self._get_text(info_primary, 'xpath:.//h1[@title]')
job['薪资'] = self._get_text(info_primary, 'xpath:.//span[contains(@class, "salary")]')
# 城市、经验、学历
info_text = info_primary.ele('tag:p')
if info_text:
job['工作城市'] = self._get_text(info_text, 'xpath:.//a[contains(@class, "text-city")]')
exp = info_text.ele('xpath:.//span[contains(@class, "text-experiece")]')
if exp:
job['经验要求'] = self.clean_text(exp.text)
edu = info_text.ele('xpath:.//span[contains(@class, "text-degree")]')
if edu:
job['学历要求'] = self.clean_text(edu.text)
# 职位描述和标签
job_detail = page.ele('xpath://div[@class="job-detail-section"]', timeout=5)
if job_detail:
job['职位描述'] = self._get_text(job_detail, 'xpath:.//div[contains(@class, "job-sec-text")]')
# 技能标签
skills = []
keyword_list = job_detail.ele('xpath:.//ul[contains(@class, "job-keyword-list")]')
if keyword_list:
for item in keyword_list.eles('xpath:.//li', timeout=1):
skills.append(self.clean_text(item.text))
if skills:
job['岗位标签'] = '、'.join(skills)
# 公司信息
company = page.ele('xpath://div[@class="sider-company"]', timeout=5)
if company:
job['公司名称'] = self._get_text(company, 'xpath:.//a[@ka="job-detail-company_custompage"]')
job['所属行业'] = self._get_text(company, 'xpath:.//a[@ka="job-detail-brandindustry"]')
# 在company中查找内部包含class为"icon-stage"的i标签的p元素
job['融资情况'] = self._get_text(company, 'xpath:.//p[i[contains(@class, "icon-stage")]]')
job['公司规模'] = self._get_text(company, 'xpath:.//p[i[contains(@class, "icon-scale")]]')
# 岗位标签
welfare = []
job_tags = page.ele('xpath://div[contains(@class, "job-tags")]', timeout=1)
if job_tags:
for span in job_tags.eles('xpath:.//span', timeout=1):
if span.text.strip():
welfare.append(self.clean_text(span.text))
job['岗位标签'] = '、'.join(welfare)
# 招聘负责人信息(姓名、活跃状态、招聘者职位)
boss = page.ele('xpath://div[@class="job-boss-info"]', timeout=5)
if boss:
# 获取姓名元素
name_elem = boss.ele('xpath:.//h2[@class="name"]')
if name_elem:
full_text = name_elem.text.strip()
# 获取状态元素(可能是boss-active-time或boss-online-tag)
status_elem = boss.ele('xpath:.//span[contains(@class, "boss-active-time") or contains(@class, "boss-online-tag")]', timeout=1)
status = status_elem.text.strip() if status_elem else ''
# 如果状态在姓名里,从姓名中移除
name = full_text.replace(status, '').strip() if status and status in full_text else full_text
job['招聘负责人'] = name
job['活跃状态'] = status
boss_attr = self._get_text(boss, 'xpath:.//div[@class="boss-info-attr"]')
if boss_attr:
job['招聘者职位'] = boss_attr.split('·', 1)[-1].strip() if '·' in boss_attr else boss_attr
except Exception as e:
logger.warning(f"解析职位详情失败: {e}")
return job
def _get_text(self, element, selector: str) -> str:
"""安全获取元素文本"""
try:
elem = element.ele(selector, timeout=1)
return self.clean_text(elem.text) if elem else ''
except:
return ''
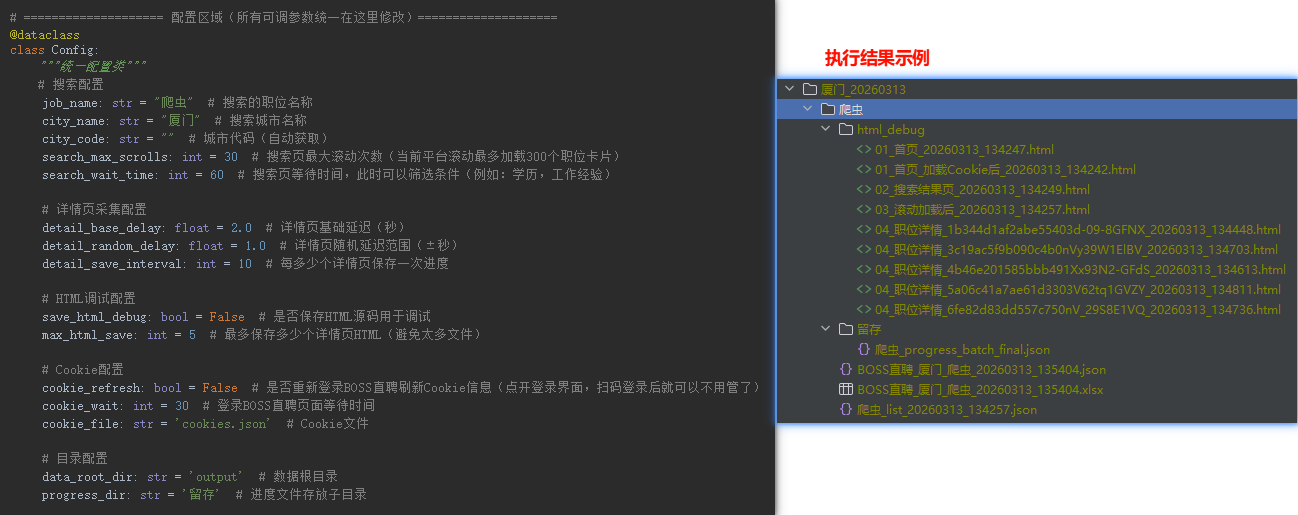
5.结果展示
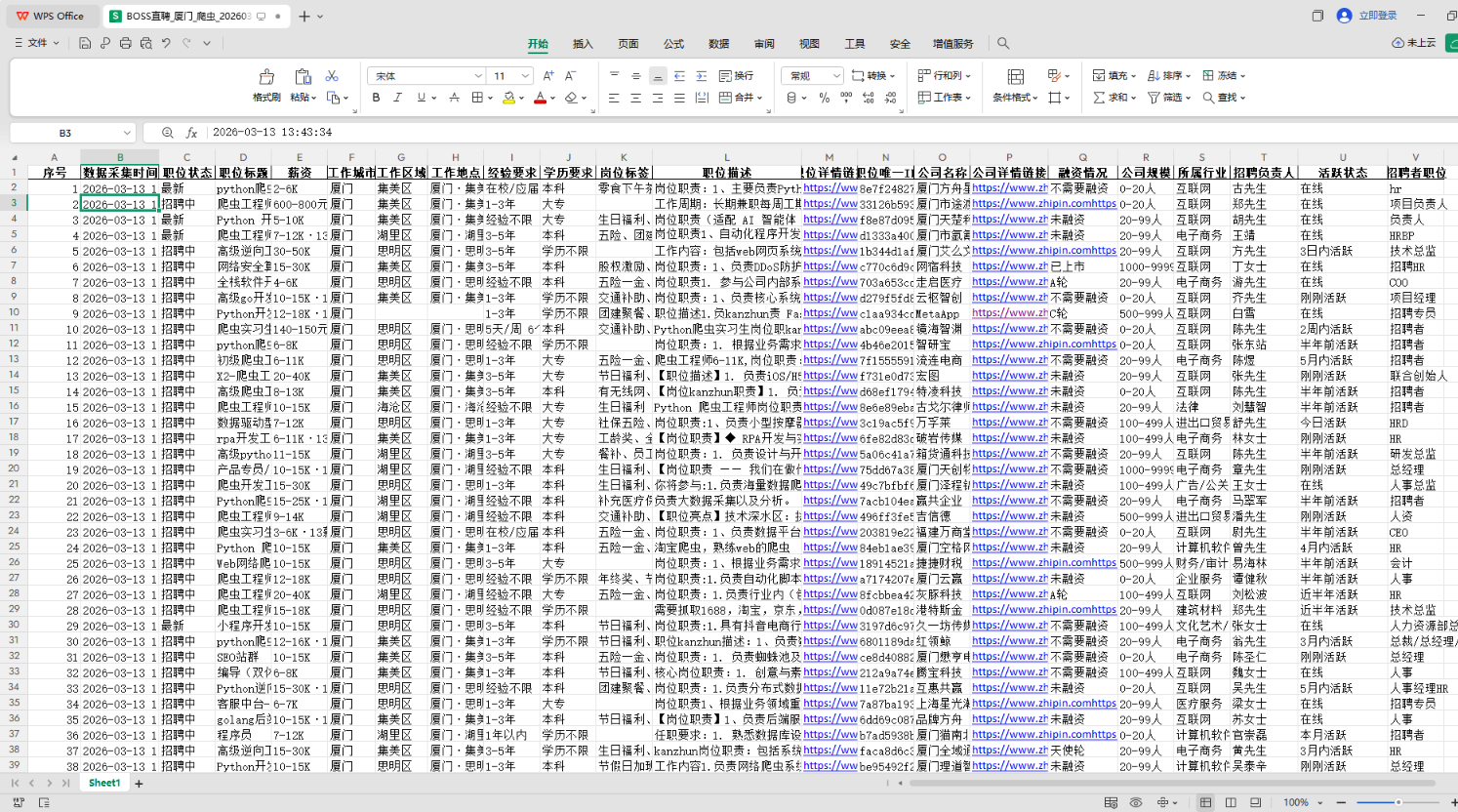
岗位职责
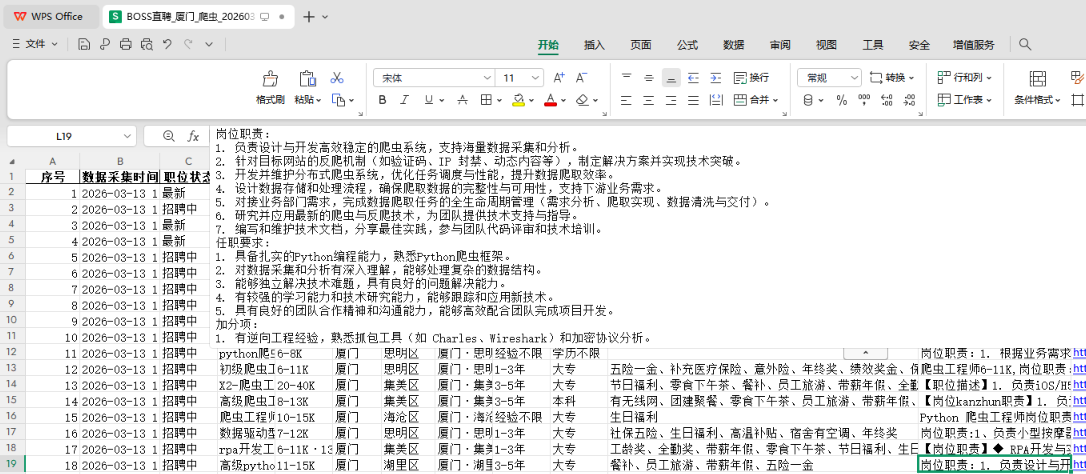
基础参数与结果文件

