官方文档:https://doris.apache.org/zh-CN/docs/dev/get-starting/quick-start/
1.Doris 简介
1.1 Doris 概述
Apache Doris 由百度大数据部研发(之前叫百度 Palo,2018 年贡献到 Apache 社区后,更名为 Doris ),在百度内部,有超过 200 个产品线在使用,部署机器超过 1000 台,单一业务最大可达到上百 TB。
Apache Doris 是一个现代化的 MPP(Massively Parallel Processing,即大规模并行处理) 分析型(OLAP)数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris 的分布式架构非常简洁,易于运维,并且可以支持 10PB 以上的超大数据集。
Apache Doris 可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
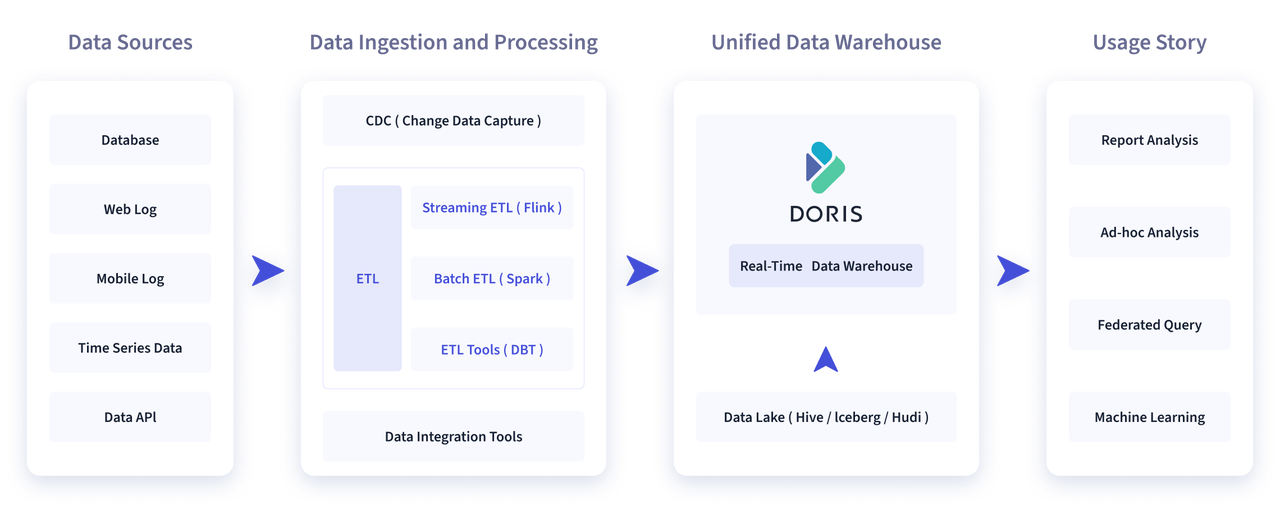
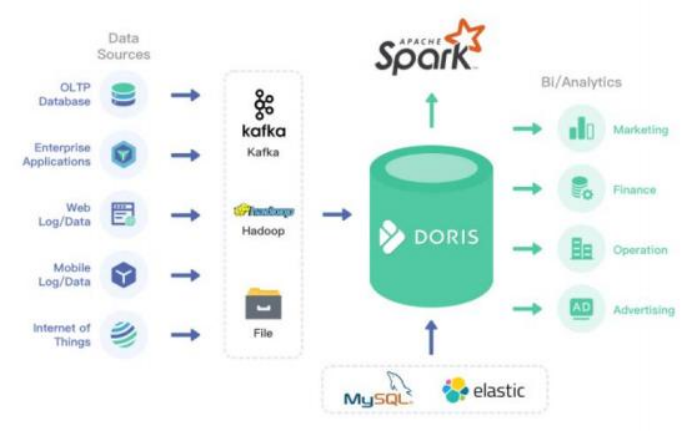

1.2 OLAP和OLTP
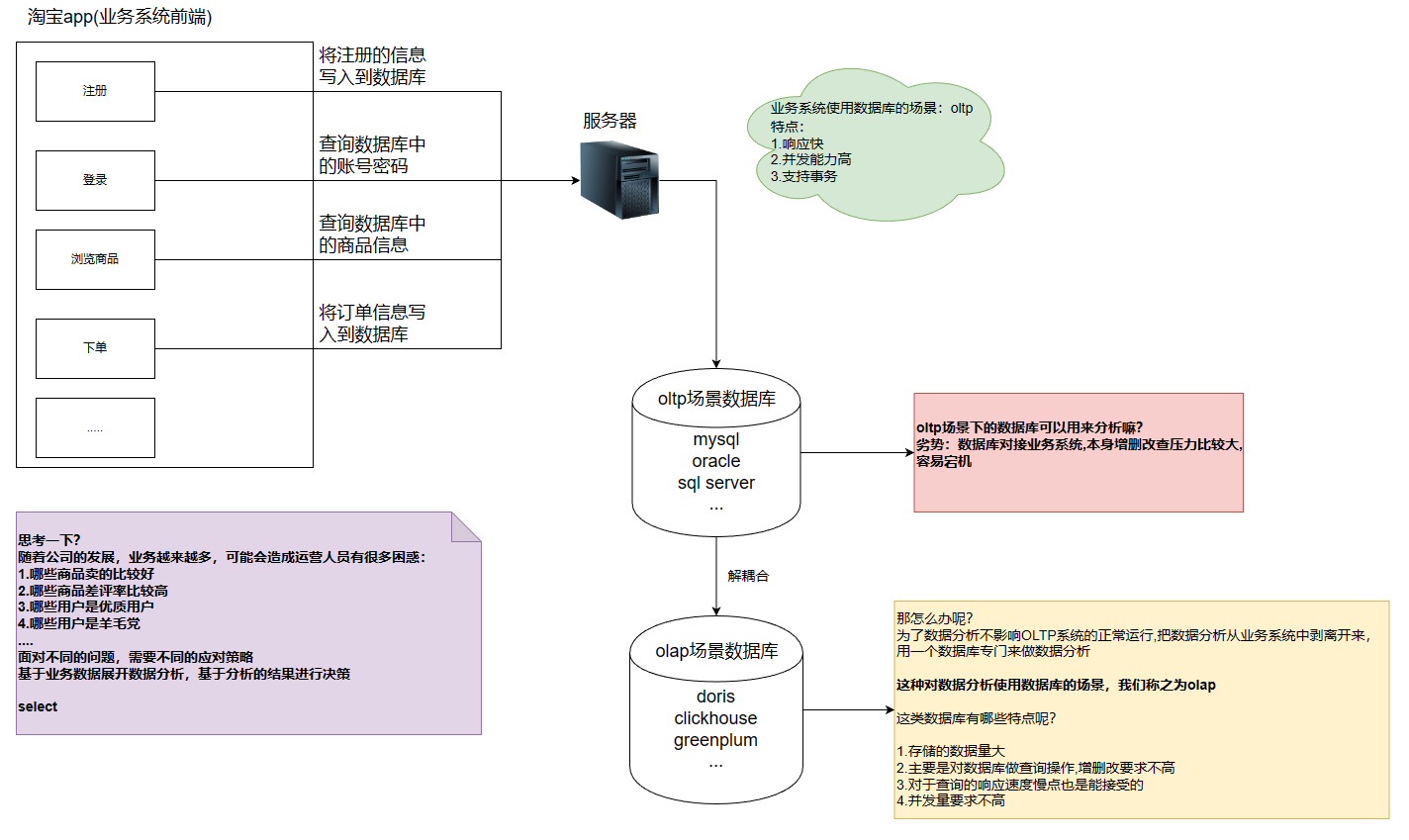
- 联机事务处理OLTP(On-Line Transaction Processing) 公司针对自己公司的业务构建出来的系统化=》淘宝
- 公司业务系统使用数据库的场景,针对业务系统数据库有大量随机的增删改查
- 高并发
- 速度要快
- 支持事务

- 联机分析处理OLAP(On-Line Analytical Processing)
- 公司的数据分析使用数据库的场景,对已经生成好的数据进行统计分析
- 一次操作都是针对的整个数据集
- 只有查这个动作,不会去增删改
- 查询的响应速度相对慢点也能接受
- 并发量要求不是太高
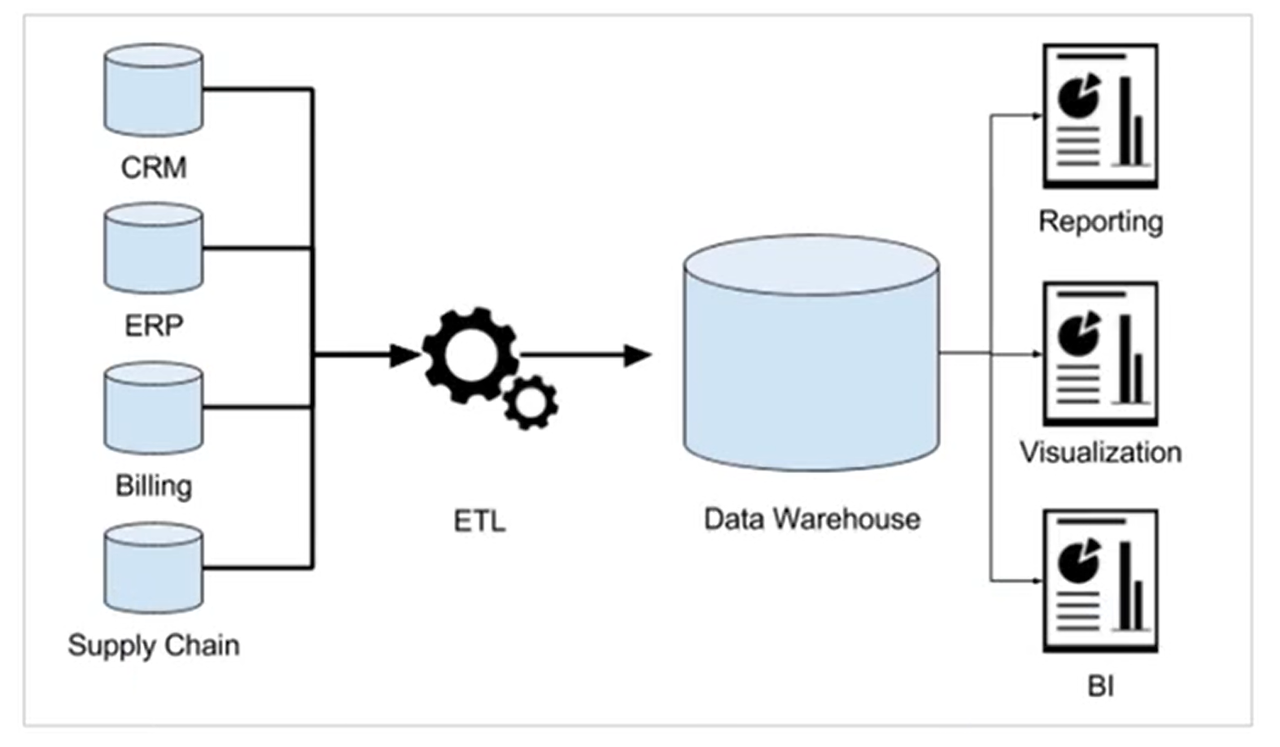
OLAP和OLTP比较 用户行为日志数据
| OLTP | OLAP | |
|---|---|---|
| 数据源 | 仅包含当前运行日常业务数据 | 整合来自多个来源的数据,包括OLTP和外部来源 |
| 目的 | 面向应用,面向业务,支撑事务 | 面向主题,面向分析,支持分析决策 |
| 焦点 | 当下 | 主要面向过去,面向历史(实时数仓除外) |
| 任务 | 增删改查 | 主要是用于读,select查询,写操作很少 |
| 响应时间 | 毫秒 | 秒,分钟,小时,天,这些取决于数据量和查询的复杂程度 |
| 数据量 | 小数据,MB,GB | 大数据,TP,PB |
常见的开源OLAP引擎
| 开源OLAP引擎 | 优点 | 缺点 | 技术融合成本 | 易用性 | 使用场景 | 运维成本 | 引擎类型 |
|---|---|---|---|---|---|---|---|
| ClickHouse | 列式存储单极性彪悍保留明细数据 | 分布式集群在线扩展支持不佳运维成本极高 | 高 | 非标协议接口 | 全面 | 高 | 纯列存OLAP |
| Druid | 实时数据摄入列式存储和位图索引多租户和高并发 | OLAP性能分场景表现差异大使用门槛高仅支持聚合查询 | 高 | 非标协议接口 | 局限 | 高 | MOLAP |
| TiDB | HTAP混合数据库同时支持明细和聚合查询高度兼容mysql | 非列式存储OLAP能力不足 | 低 | SQL标准 | 全面 | 低 | 纯列存OLAP |
| Kylin | 与计算引擎,可以对数据一次聚合多次查询支持数据规模超大易用性强,支持标准sql性能强,查询数据快 | 需要依赖hadoop生态仅支持聚合查·询不支持adhoc查询不支持join和对数据的更新 | 高 | SQL标准 | 局限 | 高 | MOLAP |
| Doris | GooleMesa+Apache Impa+ORCFile/Parquet主键更新支持Rollup Table高并发和高通图的Ad-hoc查询支持聚合+明细数据查询无外部系统依赖 | 成熟度不够 | 低 | 兼容mysql访问协议 | 全面 | 低 | HOLAP |
1.3 使用场景
- 报表分析
- 实时看板 (Dashboards)
- 面向企业内部分析师和管理者的报表
- 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS ,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 亿行数据,查询并发 QPS 上万,99 分位的查询延时 150ms。
- 即席查询(Ad-hoc Query):面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
- 统一数仓构建 :一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由 Spark、Hive、Hbase、Phoenix 组成的旧架构,架构大大简化。
- 数据湖联邦查询:通过外表的方式联邦分析位于 Hive、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升
1.4 优势

1.5 架构
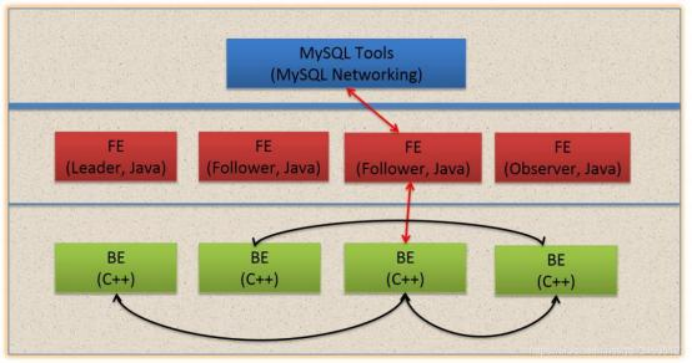
Doris 的架构很简洁,只设 FE(Frontend)前端进程、BE(Backend)后端进程两种角色、两个后台的服务进程,不依赖于外部组件,方便部署和运维,FE、BE 都可在线性扩展。
- FE(Frontend):存储、维护集群元数据;负责接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果。主要有三个角色:
- Leader 和 Follower:主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
- Observer:用来扩展查询节点,同时起到元数据备份的作用。如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取。
- BE(Backend):负责物理数据的存储和计算;依据 FE 生成的物理计划,分布式地执行查询。数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
- MySQL Client:Doris 借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC 以及 MySQL 的客户端,都可以直接访问 Doris。
- Broker:一个独立的无状态进程。封装了文件系统接口,提供 Doris 读取远端存储系统中文件的能力,包括 HDFS,S3,BOS 等。
2.编译与安装
安装 Doris,需要先通过源码编译,主要有两种方式:使用 Docker 开发镜像编译(推荐)、直接编译。
直接编译的方式,可以参考官网:https://doris.apache.org/zh-CN/docs/dev/install/source-install/compilation-general
2.1 安装 Docker 环境
1)Docker 要求 CentOS 系统的内核版本高于 3.10 ,首先查看系统内核版本是否满足
uname -r
2)使用 root 权限登录系统,确保 yum 包更新到最新
sudo yum update -y
3)假如安装过旧版本, 先卸载旧版本
sudo yum remove docker docker-common docker-selinux docker-engine
4)安装 yum-util 工具包和 devicemapper 驱动依赖
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
5)设置 yum 源(加速 yum 下载速度)
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
如果连接超时, 可以使用 alibaba 的镜像源:
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
6)查看所有仓库中所有 docker 版本, 并选择特定版本安装,一般可直接安装最新版
yum list docker-ce --showduplicates | sort -r
7)安装 docker
(1)安装最新稳定版本的方式:
sudo yum install docker-ce -y
#安装的是最新稳定版本,因为 repo 中默认只开启 stable 仓库
(2)安装指定版本的方式:
sudo yum install <FQPN> -y
# 例如:
sudo yum install docker-ce-20.10.11.ce -y
8)启动并加入开机启动
#启动 docker
sudo systemctl start docker
#加入开机自启动
sudo systemctl enable docker
9)查看 Version,验证是否安装成功
docker version
若出现 Client 和 Server 两部分内容, 则证明安装成功。
2.2 使用Docker开发镜像编译
1)下载源码并解压
通过 wget 下载(或者手动上传下载好的压缩包)。
wget http://archive.apache.org/dist/incubator/doris/0.15.0-incubating/apache-doris-0.15.0-incubating-src.tar.gz
解压到/opt/software/
tar -zxvf apache-doris-0.15.0-incubating-src.tar.gz -C /opt/software
2)下载 Docker 镜像
docker pull apache/incubator-doris:build-env-for-0.15.0
可以通过以下命令查看镜像是否下载完成
docker images
3)挂载本地目录运行镜像
以挂载本地 Doris 源码目录的方式运行镜像, 这样编译的产出二进制文件会存储在宿主 机中, 不会因为镜像退出而消失。同时将镜像中 maven 的 .m2 目录挂载到宿主机目录, 以防止每次启动镜像编译时,重复下载 maven 的依赖库
sudo docker run -it \
-v /opt/software/.m2:/root/.m2 \
-v /opt/software/apache-doris-0.15.0-incubating-src:/root/apache-doris-0.15.0-incubating-src \
apache/incubator-doris:build-env-for-0.15.0
4)切换到 JDK 8
echo $JAVA_HOME
alternatives --set java java-1.8.0-openjdk.x86_64
alternatives --set javac java-1.8.0-openjdk.x86_64
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
echo $JAVA_HOME
5)准备 Maven 依赖
编译过程会下载很多依赖,可以将我们准备好的 doris-repo.tar.gz 解压到 Docker 挂载的对应目录, 来避免下载依赖的过程, 加速编译
tar -zxvf doris-repo.tar.gz -C /opt/software
也可以通过指定阿里云镜像仓库来加速下载:
vim /opt/software/apache-doris-0.15.0-incubating-src/fe/pom.xml
# 在<repositories>标签下添加:
<repository>
<id>aliyun</id> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> </repository>
vim /opt/software/apache-doris-0.15.0-incubating-src/be/pom.xml
# 在<repositories>标签下添加:
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url> </repository>
6)编译 Doris
sh build.sh
如果是第一次使用 build-env-for-0.15.0 或之后的版本, 第一次编译的时候要使用如下命令:
sh build.sh --clean --be --fe --ui
因为 build-env-for-0.15.0 版本镜像升级了 thrift(0.9 -> 0.13),需要通过–clean 命令强制使用新版本的 thrift 生成代码文件,否则会出现不兼容的代码
2.3 安装要求
2.3.1 软硬件需求
- Linux 操作系统要求
| Linux 系统 | 版本 |
|---|---|
| CentOS | 7.1 及以上 |
| Ubuntu | 16.04 及以上 |
- 软件需求
| 软件 | 版本 |
|---|---|
| Java | 1.8 及以上 |
| GCC | 4.8.2 及以上 |
- 测试环境硬件配置需求
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量 |
|---|---|---|---|---|---|
| Frontend | 8核+ | 8GB+ | SSD 或 SATA,10GB+ * | 千兆网卡 | 1 |
| Backend | 8核+ | 16GB+ | SSD 或 SATA,50GB+ * | 千兆网卡 | 1-3 * |
- 生产环境硬件配置需求
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| Frontend | 16核+ | 64GB+ | SSD 或 RAID 卡,100GB+ * | 万兆网卡 | 1-5 * |
| Backend | 16核+ | 64GB+ | SSD 或 SATA,100G+ * | 万兆网卡 | 10-100 * |
- 注意事项
(1)FE 的磁盘空间主要用于存储元数据,包括日志和 image。通常从几百 MB 到几个 GB 不等。
(2)BE 的磁盘空间主要用于存放用户数据, 总磁盘空间按用户总数据量* 3(3 副本) 计算, 然后再预留额外 40%的空间用作后台 compaction 以及一些中间数据的存放。
(3)一台机器上可以部署多个 BE 实例, 但是只能部署一个 FE。如果需要 3 副本数 据, 那么至少需要 3 台机器各部署一个 BE 实例(而不是 1 台机器部署 3 个 BE 实例)。多 个 FE 所在服务器的时钟必须保持一致(允许最多5 秒的时钟偏差)
(4)测试环境也可以仅适用一个 BE 进行测试。实际生产环境,BE 实例数量直接决定 了整体查询延迟。
(5)所有部署节点关闭 Swap。
(6)FE 节点数据至少为 1(1 个 Follower)。当部署 1 个 Follower 和 1 个 Observer 时, 可以实现读高可用。当部署 3 个 Follower 时,可以实现读写高可用(HA)。
(7)Follower 的数量必须为奇数,Observer 数量随意。
(8)根据以往经验,当集群可用性要求很高时(比如提供在线业务), 可以部署 3 个 Follower 和 1-3 个 Observer。如果是离线业务, 建议部署 1 个 Follower 和 1-3 个 Observer。
(9)Broker 是用于访问外部数据源(如 HDFS)的进程。通常,在每台机器上部署一 个 broker 实例即可。
2.3.2 默认端口
| 实例名称 | 端口名称 | 默认端口 | 通讯方向 | 说明 |
|---|---|---|---|---|
| BE | be_port | 9060 | FE–>BE | BE 上 thrift server 的端口,用于接收来自 FE 的请求 |
| BE | webserver_port | 8040 | BE<–>FE | BE 上的 http server 端口 |
| BE | heartbeat_service_port | 9050 | FE–>BE | BE 上心跳服务端口,用于接收来自 FE 的心跳 |
| BE | brpc_prot* | 8060 | FE<–>BE,BE<–>BE | BE 上的 brpc 端口,用于 BE 之间通信 |
| FE | http_port | 8030 | FE<–>FE ,用户<–> FE | FE 上的 http_server 端口 |
| FE | rpc_port | 9020 | BE–>FE ,FE<–>FE | FE 上 thirft server 端口 |
| FE | query_port | 9030 | 用户<–> FE | FE 上的 mysql server 端口 |
| FE | edit_log_port | 9010 | FE<–>FE | FE 上 bdbje 之间通信用的端口 |
| Broker | broker_ipc_port | 8000 | FE–>BROKER,BE–>BROKER | Broker 上的 thrift server,用于接收请求 |
当部署多个 FE 实例时,要保证 FE 的 http_port 配置相同。
部署前请确保各个端口在应有方向上的访问权限。
2.4 集群部署
| 主机 1 | 主机 2 | 主机 3 |
|---|---|---|
| FE(LEADER) | FE(FOLLOWER) | FE(OBSERVER) |
| BE | BE | BE |
| BROKER | BROKER | BROKER |
生产环境建议 FE 和 BE 分开
2.4.1 创建目录并拷贝编译后的文件
1)创建目录并拷贝编译后的文件
mkdir /opt/module/apache-doris-0.15.0
cp -r /opt/software/apache-doris-0.15.0-incubating-src/output /opt/module/apache-doris-0.15.0
2)修改可打开文件数(每个节点)
sudo vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 65535
重启永久生效, 也可以用 ulimit -n 65535 临时生效
2.4.2 部署 FE 节点
1)创建 fe 元数据存储的目录
mkdir /opt/module/apache-doris-0.15.0/doris-meta
2)修改 fe 的配置文件
vim /opt/module/apache-doris-0.15.0/fe/conf/fe.conf
#配置文件中指定元数据路径:
meta_dir = /opt/module/apache-doris-0.15.0/doris-meta
#修改绑定 ip(每台机器修改成自己的 ip)
priority_networks = 192.168.1.102/24
注意:
- 生产环境强烈建议单独指定目录不要放在 Doris 安装目录下,最好是单独的磁盘(如果有 SSD 最好)。
- 如果机器有多个 ip, 比如内网外网, 虚拟机 docker 等, 需要进行 ip 绑定, 才能正确识 别。
- JAVA_OPTS 默认 java 最大堆内存为 4GB,建议生产环境调整至 8G 以上。
3)启动 hadoop102 的 FE
/opt/module/apache-doris-0.15.0/fe/bin/start_fe.sh --daemon
2.4.3 配置 BE 节点
1)分发 BE
scp -r /opt/module/apache-doris-0.15.0/be hadoop103:/opt/module
scp -r /opt/module/apache-doris-0.15.0/be hadoop104:/opt/module
2)创建 BE 数据存放目录 (每个节点)
mkdir /opt/module/apache-doris-0.15.0/doris-storage1
mkdir /opt/module/apache-doris-0.15.0/doris-storage2
3)修改 BE 的配置文件(每个节点)
vim /opt/module/apache-doris-0.15.0/be/conf/be.conf
#配置文件中指定数据存放路径:
storage_root_path = /opt/module/apache-doris-0.15.0/doris-storage1;/opt/module/apache-doris-0.15.0/doris-storage2
#修改绑定 ip(每台机器修改成自己的 ip)
priority_networks = 192.168.1.102/24
注意:
storage_root_path 默认在 be/storage 下,需要手动创建该目录。多个路径之间使用英文状 态的分号;分隔(最后一个目录后不要加)
可以通过路径区别存储目录的介质, HDD 或 SSD。可以添加容量限制在每个路径的末尾,通过英文状态逗号,隔开,如:
storage_root_path=/home/disk1/doris.HDD,50;/home/disk2/doris.SSD,10;/home/disk2/doris
说明:
/home/disk1/doris.HDD,50,表示存储限制为 50GB ,HDD;
/home/disk2/doris.SSD,10,存储限制为 10GB ,SSD;
/home/disk2/doris,存储限制为磁盘最大容量, 默认为 HDD
- 如果机器有多个 IP, 比如内网外网, 虚拟机 docker 等, 需要进行 IP 绑定,才能正确识别。
2.4.4 在 FE 中添加所有 BE 节点
BE 节点需要先在 FE 中添加,才可加入集群。可以使用 mysql-client 连接到 FE。
1)安装 MySQL Client
(1)创建目录
mkdir /opt/software/mysql-client/
(2)上传相关以下三个 rpm 包到/opt/software/mysql-client/
mysql-community-client-5.7.28- 1.el7.x86_64.rpm
mysql-community-common-5.7.28- 1.el7.x86_64.rpm
mysql-community-libs-5.7.28- 1.el7.x86_64.rpm
(3)检查当前系统是否安装过 MySQL
sudo rpm -qa|grep mariadb
#如果存在,先卸载
sudo rpm -e --nodeps mariadb mariadb-libs mariadb-server
(4)安装
rpm -ivh /opt/software/mysql-client/*
2)使用 MySQL Client 连接 FE
mysql -h hadoop102 -P 9030 -uroot
默认 root 无密码, 通过以下命令修改 root 密码
SET PASSWORD FOR 'root' = PASSWORD('000000');
3)添加 BE
ALTER SYSTEM ADD BACKEND "hadoop102:9050";
ALTER SYSTEM ADD BACKEND "hadoop103:9050";
ALTER SYSTEM ADD BACKEND "hadoop104:9050";
4)查看 BE 状态
SHOW PROC '/backends';
2.4.5 启动 BE
1)启动 BE (每个节点)
/opt/module/apache-doris-0.15.0/be/bin/start_be.sh --daemon
2)查看 BE 状态
#进入mysql-client
mysql -h hadoop102 -P 9030 -uroot -p000000
SHOW PROC '/backends';
Alive 为 true 表示该 BE 节点存活
2.4.6 部署 FS_Broker(可选)
Broker 以插件的形式, 独立于 Doris 部署。如果需要从第三方存储系统导入数据, 需要 部署相应的 Broker,默认提供了读取 HDFS、百度云 BOS 及 Amazon S3 的 fs_broker 。 fs_broker 是无状态的,建议每一个 FE 和 BE 节点都部署一个 Broker。
1)编译 FS_BROKER 并拷贝文件
(1)进入源码目录下的 fs_brokers 目录, 使用 sh build.sh 进行编译
(2)拷贝源码 fs_broker 的 output 目录下的相应 Broker目录到需要部署的所有节点 上,改名为: apache_hdfs_broker。建议和 BE 或者 FE 目录保持同级。
方法同 [2.2 使用Docker开发镜像编译](##2.2 使用Docker开发镜像编译),进入镜像内编译
2)启动 Broker
/opt/module/apache-doris-0.15.0/apache_hdfs_broker/bin/start_broker.sh --daemon
3)添加 Broker
要让 Doris 的 FE 和 BE 知道 Broker 在哪些节点上,通过 sql 命令添加 Broker 节 点列表。
(1)使用 mysql-client 连接启动的 FE,执行以下命令:
mysql -h hadoop102 -P 9030 -uroot -p000000
ALTER SYSTEM ADD BROKER broker_name "hadoop102:8000","hadoop103:8000","hadoop104:8000";
其中 broker_host 为 Broker 所在节点 ip ;broker_ipc_port 在 Broker 配置文件中的conf/apache_hdfs_broker.conf。
4)查看 Broker 状态
使用 mysql-client 连接任一已启动的 FE,执行以下命令查看 Broker 状态:
SHOW PROC "/brokers";
注: 在生产环境中, 所有实例都应使用守护进程启动, 以保证进程退出后, 会被自动拉 起, 如 Supervisor(opens new window)。如需使用守护进程启动, 在 0.9.0 及之前版本中,需要修改各个 start_xx.sh 脚本,去掉最后的 & 符号。从 0.10.0 版本开始,直接调用 sh start_xx.sh 启动即可。
2.5 扩容和缩容
Doris 可以很方便的扩容和缩容 FE 、BE 、Broker 实例。
2.5.1 FE 扩容和缩容
可以通过将 FE 扩容至 3 个以上节点来实现 FE 的高可用。
1)使用 MySQL 登录客户端后, 可以使用sql 命令查看 FE 状态, 目前就一台 FE
mysql -h hadoop102 -P 9030 -uroot -p000000
SHOW PROC '/frontends'\G;
也可以通过页面访问进行监控, 访问 8030,账户为 root ,密码默认为空不用填写。
2)增加 FE 节点
FE 分为 Leader ,Follower 和 Observer 三种角色。 默认一个集群,只能有一个 Leader, 可以有多个 Follower 和 Observer。其中 Leader 和 Follower 组成一个 Paxos 选择组, 如果 Leader 宕机, 则剩下的 Follower 会自动选出新的 Leader ,保证写入高可用。 Observer 同步 Leader 的数据, 但是不参加选举。
如果只部署一个 FE,则 FE 默认就是 Leader。在此基础上,可以添加若干 Follower 和Observer。
ALTER SYSTEM ADD FOLLOWER "hadoop103:9010";
ALTER SYSTEM ADD OBSERVER "hadoop104:9010";
3)配置及启动 Follower 和 Observer
第一次启动时, 启动命令需要添加参–helper leader 主机: edit_log_port:
(1)分发 FE,修改 FE 的配置(同 [2.4.2 部署 FE 节点](###2.4.2 部署 FE 节点))
scp -r /opt/module/apache-doris-0.15.0/fe hadoop103:/opt/module/apache-doris-0.15.0
scp -r /opt/module/apache-doris-0.15.0/fe hadoop104:/opt/module/apache-doris-0.15.0
(2)在 hadoop2 启动 Follower
/opt/module/apache-doris-0.15.0/fe/bin/start_fe.sh --helper hadoop102:9010 --daemon
(3)在 hadoop3 启动 Observer
/opt/module/apache-doris-0.15.0/fe/bin/start_fe.sh --helper hadoop102:9010 --daemon
4)查看运行状态
使用 mysql-client 连接到任一已启动的 FE
SHOW PROC '/frontends'\G;
5)删除 FE 节点命令
ALTER SYSTEM DROP FOLLOWER[OBSERVER] "fe_host:edit_log_port";
注意: 删除 Follower FE 时,确保最终剩余的Follower (包括 Leader)节点为奇数
2.5.2 BE 扩容和缩容
1)增加 BE 节点
在 MySQL 客户端,通过 ALTER SYSTEM ADD BACKEND 命令增加 BE 节点。
2)DROP 方式删除 BE 节点(不推荐)
ALTER SYSTEM DROP BACKEND "be_host:be_heartbeat_service_port";
注意:DROP BACKEND 会直接删除该 BE,并且其上的数据将不能再恢复!!!所以 我们强烈不推荐使用 DROP BACKEND 这种方式删除 BE 节点。当你使用这个语句时, 会 有对应的防误操作提示。
3)DECOMMISSION 方式删除 BE 节点(推荐)
ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
该命令用于安全删除 BE 节点。命令下发后, Doris 会尝试将该 BE 上的数据向其他 BE 节点迁移, 当所有数据都迁移完成后, Doris 会自动删除该节点。
该命令是一个异步操作。执行后,可以通过 SHOW PROC ‘/backends’; 看到该 BE 节点的 isDecommission 状态为true 。表示该节点正在进行下线。
该命令不一定执行成功。比如剩余 BE 存储空间不足以容纳下线 BE 上的数据, 或者剩余机器数量不满足最小副本数时,该命令都无法完成,并且 BE 会一直处于 isDecommission 为 true 的状态。
DECOMMISSION 的进度,可以通过 SHOW PROC ‘/backends’; 中的 TabletNum 查 看,如果正在进行, TabletNum 将不断减少。
该操作可以通过如下命令取消:
CANCEL DECOMMISSION BACKEND “be_host:be_heartbeat_service_port”;
取消后,该 BE 上的数据将维持当前剩余的数据量。后续 Doris 重新进行负载均衡。
2.5.3 Broker 扩容缩容
Broker 实例的数量没有硬性要求。通常每台物理机部署一个即可。 Broker 的添加和删除可以通过以下命令完成:
ALTER SYSTEM ADD BROKER broker_name "broker_host:broker_ipc_port";
ALTER SYSTEM DROP BROKER broker_name "broker_host:broker_ipc_port";
ALTER SYSTEM DROP ALL BROKER broker_name;
Broker 是无状态的进程,可以随意启停。当然,停止后, 正在其上运行的作业会失败, 重试即可。
doris集群启停脚本
fe.sh
#! /bin/bash
#1、判断参数是否存在
if [ $# -lt 1 ]
then
echo "必须输入参数....."
exit
fi
#2、根据输入参数执行逻辑
case $1 in
"start")
for host in hadoop102 hadoop103 hadoop104
do
echo "=================start $host fe==============="
ssh $host "/opt/module/apache-doris-0.15.0/fe/bin/start_fe.sh --daemon"
done
;;
"stop")
for host in hadoop102 hadoop103 hadoop104
do
echo "=================stop $host fe==============="
ssh $host "/opt/module/apache-doris-0.15.0/fe/bin/stop_fe.sh"
done
;;
"status")
for host in hadoop102 hadoop103 hadoop104
do
pid=$(ssh $host "ps -ef | grep PaloFe | grep -v grep")
[ "$pid" ] && echo "fe进程正常" || echo "fe进程不存在或者异常"
done
;;
*)
echo "参数输入错误,请输入start|stop|status"
;;
esac
be.sh
#! /bin/bash
#1、判断参数是否存在
if [ $# -lt 1 ]
then
echo "必须输入参数....."
exit
fi
#2、根据输入参数执行逻辑
case $1 in
"start")
for host in hadoop102 hadoop103 hadoop104
do
echo "=================start $host be==============="
ssh $host "/opt/module/apache-doris-0.15.0/be/bin/start_be.sh --daemon"
done
;;
"stop")
for host in hadoop102 hadoop103 hadoop104
do
echo "=================stop $host be==============="
ssh $host "/opt/module/apache-doris-0.15.0/be/bin/stop_be.sh"
done
;;
"status")
for host in hadoop102 hadoop103 hadoop104
do
pid=$(ssh $host "ps -ef | grep palo_be | grep -v grep")
[ "$pid" ] && echo "be进程正常" || echo "be进程不存在或者异常"
done
;;
*)
echo "参数输入错误,请输入start|stop|status"
;;
esac
broker.sh
#! /bin/bash
#1、判断参数是否存在
if [ $# -lt 1 ]
then
echo "必须输入参数....."
exit
fi
#2、根据输入参数执行逻辑
case $1 in
"start")
for host in hadoop102 hadoop103 hadoop104
do
echo "=================start $host fs_broker==============="
ssh $host "/opt/module/apache-doris-0.15.0/apache_hdfs_broker/bin/start_broker.sh --daemon"
done
;;
"stop")
for host in hadoop102 hadoop103 hadoop104
do
echo "=================stop $host fs_broker==============="
ssh $host "/opt/module/apache-doris-0.15.0/apache_hdfs_broker/bin/stop_broker.sh"
done
;;
"status")
for host in hadoop102 hadoop103 hadoop104
do
pid=$(ssh $host "ps -ef | grep BrokerBootstrap | grep -v grep")
[ "$pid" ] && echo "fs_broker进程正常" || echo "fs_broker进程不存在或者异常"
done
;;
*)
echo "参数输入错误,请输入start|stop|status"
;;
esac

