简介
用于搬迁文档到Halo 博客系统(通过文章导入工具批量上传md文档)
这是一个用于批量下载 Markdown 文件中图片外链的工具脚本。它可以自动扫描指定目录下的所有 Markdown 文件,提取其中的图片链接(http/https),下载到本地,并自动将 Markdown 文件中的图片链接替换为本地路径。
主要功能
- ✅ 递归扫描指定目录下的所有
.md文件 - ✅ 提取 Markdown 中的图片外链(支持
语法) - ✅ 下载图片到本地(支持重试机制,最多3次)
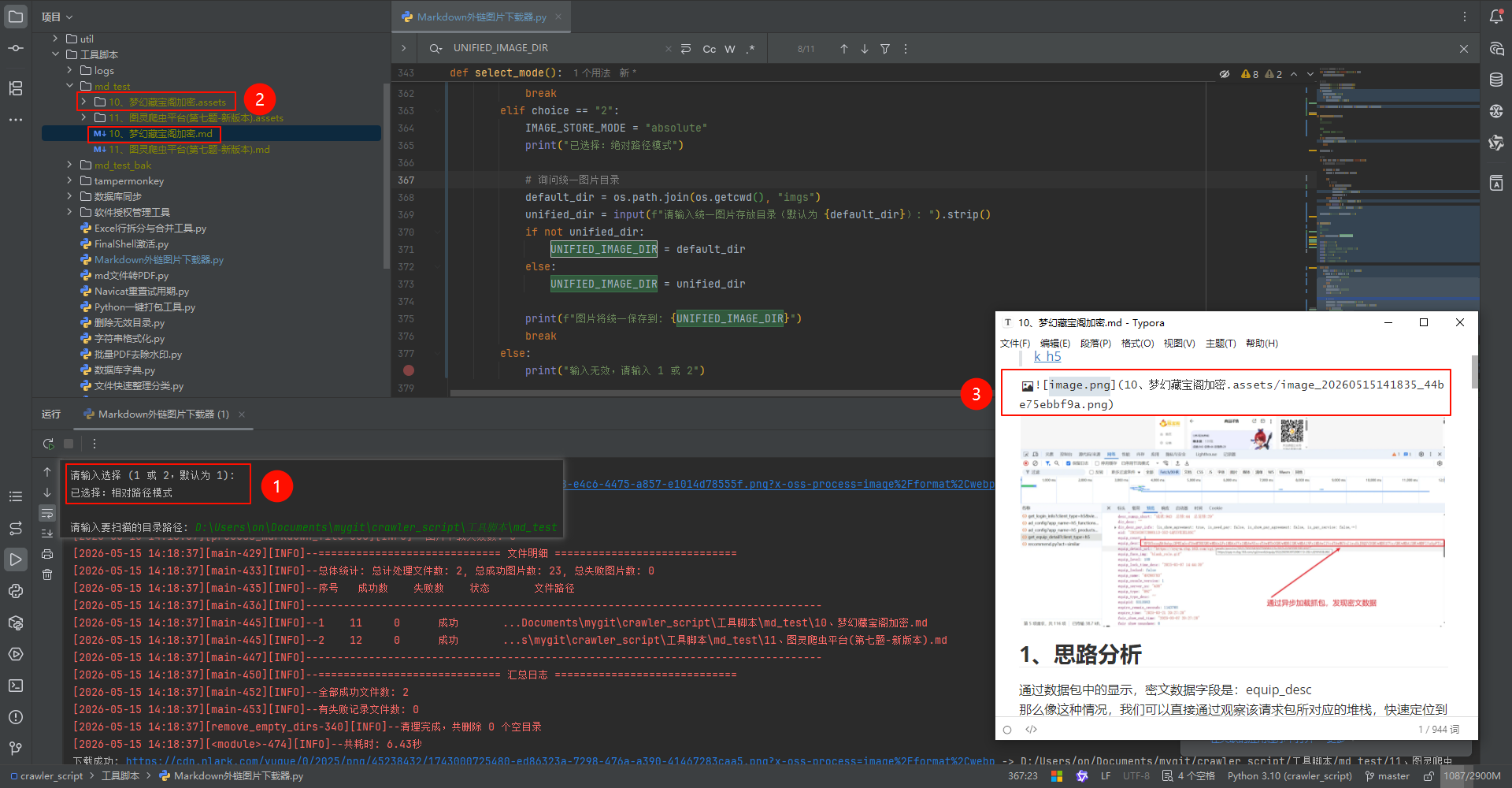
- ✅ 支持两种图片存储模式:
- 相对路径模式:每个 Markdown 文件对应一个
.assets目录,使用相对路径引用 - 绝对路径模式:所有图片统一存放在指定目录,保持原目录结构,使用绝对路径引用
- 相对路径模式:每个 Markdown 文件对应一个
- ✅ 自动替换 Markdown 文件中的图片链接
- ✅ 自动清理下载过程中产生的空目录
- ✅ 生成详细的处理日志(控制台 + 文件)
结果展示
相对路径模式
md文件目录/
├── 文档1.md
├── 文档1.assets/
│ ├── image_20250106143022_a1b2c3.png
│ └── image_20250106143025_d4e5f6.jpg
├── 子目录/
│ ├── 文档2.md
│ └── 文档2.assets/
│ └── image_20250106143030_g7h8i9.png
Markdown 中的链接会变成:

绝对路径模式
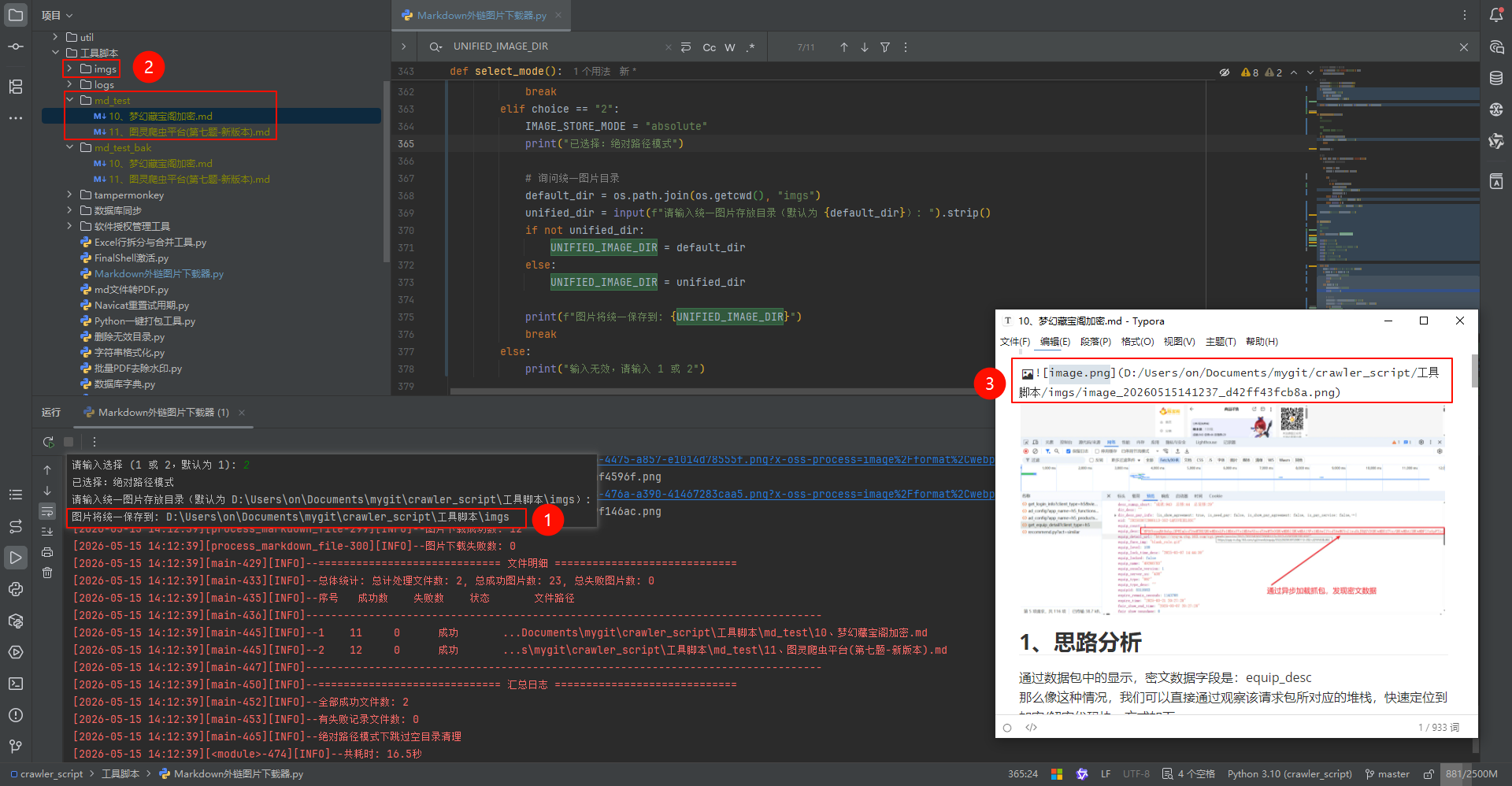
md文件目录/
├── 文档1.md
├── 子目录/
│ ├── 文档2.md
指定的图片目录/
├── image_20250106143022_a1b2c3.png
├── image_20250106143025_d4e5f6.jpg
├── image_20250106143030_g7h8i9.png
Markdown 中的链接会变成:

注意事项
- 备份重要文件:脚本会直接修改原始 Markdown 文件,建议运行前备份
- 网络要求:需要能够访问外链图片的服务器
- 文件名唯一性:下载的图片会使用
image_时间戳_UUID格式命名,避免重名冲突 - 权限问题:确保对目标目录有读写权限
常见问题
Q: 某些图片下载失败怎么办?
A: 脚本会保留原始链接,失败的文件会在汇总日志中列出。可以:
- 检查网络连接
- 确认图片 URL 是否有效
- 手动下载失败的图片
Q: 如何只处理特定文件?
A: 可以将需要处理的 Markdown 文件单独放在一个目录中,然后扫描该目录。
源码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Time : 2025/01/06 14:52 周一
Author : Leo
Version: v1.0
Desc : Markdown外链图片下载器
功能:
1. 扫描指定目录下的所有 Markdown 文件
2. 提取文件中的所有图片外链(http/https)
3. 下载图片到本地(支持两种引用模式)
- 相对路径模式:下载到每个文件对应的 .assets 目录,使用相对路径引用
- 绝对路径模式:统一下载到指定目录,使用绝对路径引用
4. 自动替换 Markdown 中的图片链接为本地路径
5. 支持下载重试机制,自动清理空目录
"""
import datetime
import os
import re
import time
import uuid
import requests
from urllib.parse import urlparse
# 全局配置:图片存储模式
# mode = "relative" # 相对路径模式:下载到每个文件对应的 .assets 目录下,使用相对路径
# mode = "absolute" # 绝对路径模式:统一下载到指定目录下,使用绝对路径
IMAGE_STORE_MODE = "relative" # 默认使用相对路径模式
UNIFIED_IMAGE_DIR = "" # 统一图片目录,当 IMAGE_STORE_MODE = "absolute" 时必须设置
def get_logger(name=None, log_dir="logs"):
"""
创建一个日志记录器对象,并设置日志输出到控制台和文件。
:param name: 可选,日志记录器的名称。如果为 None,则自动获取调用脚本的名称。
:param log_dir: 可选,日志记录器的保存目录。默认为logs
:return: 配置好的日志记录器对象。
"""
import logging
import inspect
import os
# 获取调用脚本的文件名(不含扩展名)
if name is None:
frame = inspect.stack()[1]
module = inspect.getmodule(frame[0])
script_name = os.path.splitext(os.path.basename(module.__file__))[0] if module else "unknown_script"
else:
script_name = name
# 创建一个日志记录器对象
logger = logging.getLogger(name)
# 定义日志格式,包含时间戳、日志级别、文件名、函数名、行号和日志消息
formatter = logging.Formatter(
# '[%(asctime)s-%(levelname)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
'[%(asctime)s][%(funcName)s-%(lineno)d][%(levelname)s]--%(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
# 设置日志记录器的日志级别为 INFO
# logger.setLevel(logging.DEBUG)
logger.setLevel(logging.INFO)
# 检查日志记录器是否已经有处理程序,防止重复添加
if not logger.handlers:
# 控制台日志(输出到屏幕)
console_handler = logging.StreamHandler()
console_handler.setFormatter(formatter)
logger.addHandler(console_handler)
# 创建日志目录
os.makedirs(log_dir, exist_ok=True)
# 创建文件处理程序,用于将日志写入指定文件
file_handler = logging.FileHandler(
filename=os.path.join(log_dir, f"{script_name}.txt"), # 设置日志文件路径
mode='a', # 文件模式,'a' 表示追加模式,不会覆盖已有内容
encoding='utf-8' # 日志文件的编码格式为 UTF-8
)
file_handler.setFormatter(formatter) # 设置日志处理程序的格式化器为上面定义的 formatter
logger.addHandler(file_handler) # 将该文件处理程序添加到日志记录器中处理日志
return logger
def get_file_link(file_path, link_array=None):
"""
获取文件内的所有图片链接
:param file_path: 文件路径
:param link_array: 存储文件内链接的数组,可传可不传
:return: 包含图片链接的列表
"""
if link_array is None:
link_array = []
# 读取文件内容
with open(file_path, "r", encoding="utf-8") as file:
file_data = file.read()
# 正则表达式匹配 Markdown 图片语法:,并确保 url 以 http 或 https 开头
file_link_reg = re.compile(r"!\[.*?\]\((https?://.*?)\)", re.IGNORECASE)
temp_result = file_link_reg.findall(file_data)
# 将匹配到的链接添加到列表中
link_array.extend(temp_result)
return link_array
def read_all_file_list(directory, files_list=None):
"""
获取指定目录下的所有 Markdown 文件列表
:param directory: 目录路径
:param files_list: 暂存读取的文件列表
:return: 包含所有 Markdown 文件路径的列表
"""
if files_list is None:
files_list = []
# 遍历目录
for item in os.listdir(directory):
full_path = os.path.join(directory, item)
if os.path.isdir(full_path):
# 如果是目录,递归读取
read_all_file_list(full_path, files_list)
else:
# 如果是 Markdown 文件,添加到列表中
if full_path.endswith(".md"):
files_list.append(full_path)
return files_list
def download_image(url, save_path, retries=3):
"""
下载图片并保存到指定路径,支持重试机制
"""
for attempt in range(retries):
try:
# 设置请求头,模拟浏览器请求
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "max-age=0",
"priority": "u=0, i",
"sec-ch-ua": '"Microsoft Edge";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
}
response = requests.get(url, headers=headers, stream=True, timeout=30)
if response.status_code == 200:
# 确保目录存在
os.makedirs(os.path.dirname(save_path), exist_ok=True)
with open(save_path, "wb") as file:
for chunk in response.iter_content(1024):
file.write(chunk)
print(f"下载成功: {url} -> {save_path}")
return True
else:
logging.warning(f"下载失败: {url} (状态码: {response.status_code})")
except Exception as e:
logging.error(f"下载失败: {url} (错误: {str(e)})")
if attempt < retries - 1:
logging.info(f"重试中... ({attempt + 1}/{retries})")
# 添加 1 秒延时
time.sleep(1)
return False
def get_image_name(file_name, has_extension, keep_original_name=False):
"""
从图片链接中提取文件名,并使用时间戳和 UUID 确保唯一性
:param keep_original_name: 是否保留原文件名(True=保留,False=重置)
"""
timestamp = datetime.datetime.now().strftime('%Y%m%d%H%M%S')
unique_suffix = uuid.uuid4().hex[:12]
# 如果不保留原文件名
if not keep_original_name:
# 如果有扩展名,使用原扩展名;否则使用 .png
if has_extension and file_name:
name, ext = os.path.splitext(file_name)
return f"image_{timestamp}_{unique_suffix}{ext}"
else:
return f"image_{timestamp}_{unique_suffix}.png"
# 保留原文件名
if not has_extension:
file_name += ".png"
# 分离文件名和扩展名
base_name, ext = os.path.splitext(file_name)
# 组合:原名_时间戳_UUID.扩展名
return f"{base_name}_{timestamp}_{unique_suffix}{ext}"
def replace_image_links(markdown_content, success_urls, failed_urls, markdown_file_path):
"""
将 Markdown 内容中的图片外链替换为相对路径或绝对路径
"""
for url, local_path in success_urls.items():
if IMAGE_STORE_MODE == "relative":
# 相对路径模式:获取相对于 Markdown 文件的相对路径
relative_path = os.path.relpath(local_path, start=os.path.dirname(markdown_file_path)).replace(os.sep, "/")
# 确保路径包含 .assets 目录
if not relative_path.startswith(f"{os.path.basename(os.path.dirname(local_path))}/"):
relative_path = f"{os.path.basename(os.path.dirname(local_path))}/{relative_path}"
markdown_content = markdown_content.replace(url, relative_path)
print(f"替换成功: {url} -> {relative_path}")
else: # absolute 模式
# 绝对路径模式:使用绝对路径(将反斜杠转换为正斜杠,保持跨平台兼容性)
absolute_path = os.path.abspath(local_path).replace(os.sep, "/")
markdown_content = markdown_content.replace(url, absolute_path)
print(f"替换成功: {url} -> {absolute_path}")
# 对于下载失败的 URL,保持原链接
for url in failed_urls:
logging.warning(f"保持原链接: {url}")
return markdown_content
def process_markdown_file(file_path):
"""
处理单个 Markdown 文件:提取图片链接、下载图片并替换链接
"""
global UNIFIED_IMAGE_DIR
# 获取文件所在目录
markdown_dir = os.path.dirname(file_path)
# 根据模式确定图片保存目录
if IMAGE_STORE_MODE == "relative":
# 相对路径模式:图片保存在 .assets 目录下
image_dir = os.path.join(markdown_dir, f"{os.path.splitext(os.path.basename(file_path))[0]}.assets")
logging.info(f"图片保存目录 (相对路径模式): {image_dir}")
else: # absolute 模式
# 绝对路径模式:图片统一保存在指定目录下
if not UNIFIED_IMAGE_DIR:
# 如果没有设置统一目录,则使用默认目录
UNIFIED_IMAGE_DIR = os.path.join(markdown_dir, "images")
logging.warning(f"未设置统一图片目录,使用默认目录: {UNIFIED_IMAGE_DIR}")
# 在统一目录下,按原 Markdown 文件的相对路径创建子目录结构
# 获取相对于扫描根目录的相对路径
rel_path = os.path.relpath(markdown_dir, start=SCAN_ROOT_DIR) if 'SCAN_ROOT_DIR' in globals() else ""
if rel_path == ".":
rel_path = ""
# 构建完整的图片保存路径
image_dir = os.path.join(UNIFIED_IMAGE_DIR, rel_path)
logging.info(f"图片保存目录 (绝对路径模式): {image_dir}")
# 创建图片保存目录(如果不存在)
os.makedirs(image_dir, exist_ok=True)
# 读取 Markdown 文件内容
with open(file_path, "r", encoding="utf-8") as file:
markdown_content = file.read()
# 提取图片外链
image_urls = get_file_link(file_path)
if not image_urls:
logging.warning(f"未找到图片外链: {file_path}")
return True, set() # 返回默认值,表示文件处理成功且没有失败的 URL
# 记录下载成功的 URL 和对应的本地路径
success_urls = {}
# 记录下载失败的 URL
failed_urls = set()
# 下载图片并保存到本地
for url in image_urls:
# 提取文件名
file_name = os.path.basename(urlparse(url).path)
# 检查文件名是否包含常见的图片扩展名
has_extension = bool(re.search(r"\.(jpg|bmp|gif|ico|pcx|jpeg|tif|png|raw|tga)$", file_name, re.IGNORECASE))
# 生成图片文件名
image_name = get_image_name(file_name, has_extension)
# 生成保存路径
save_path = os.path.join(image_dir, image_name).replace(os.sep, "/")
# 下载图片
if download_image(url, save_path):
success_urls[url] = save_path
else:
failed_urls.add(url)
# 替换 Markdown 文件中的图片外链
updated_content = replace_image_links(markdown_content, success_urls, failed_urls, file_path)
# 将更新后的内容写回 Markdown 文件 (覆盖原文件)
with open(file_path, "w", encoding="utf-8") as file:
file.write(updated_content)
# 输出执行情况
logging.info(f"图片下载成功数: {len(success_urls)}")
logging.info(f"图片下载失败数: {len(failed_urls)}")
if failed_urls:
logging.warning("失败URL:")
for url in failed_urls:
logging.warning(f" - {url}")
return len(failed_urls) == 0, failed_urls, len(success_urls), len(failed_urls)
def remove_empty_dirs(directory):
"""
递归删除指定目录下的所有空目录
Args:
directory (str): 要清理的目录路径
"""
if not os.path.isdir(directory):
logging.error(f"错误:{directory} 不是一个有效的目录")
return
deleted_count = 0
# 遍历目录
for root, dirs, files in os.walk(directory, topdown=False):
# topdown=False 表示从最深层目录开始遍历
for dir_name in dirs:
dir_path = os.path.join(root, dir_name)
try:
# 检查目录是否为空
if not os.listdir(dir_path):
os.rmdir(dir_path)
logging.info(f"已删除空目录: {dir_path}")
deleted_count += 1
except OSError as e:
logging.error(f"无法删除目录 {dir_path}: {e}")
except Exception as e:
logging.error(f"检查目录 {dir_path} 时出错: {e}")
logging.info(f"清理完成,共删除 {deleted_count} 个空目录")
def select_mode():
"""
交互式选择图片存储模式
"""
global IMAGE_STORE_MODE, UNIFIED_IMAGE_DIR
print("\n请选择图片存储模式:")
print("1. 相对路径模式(默认)")
print(" - 图片下载到每个 Markdown 文件对应的 .assets 目录下")
print(" - Markdown 中使用相对路径引用图片")
print("2. 绝对路径模式")
print(" - 图片统一下载到指定目录下")
print(" - Markdown 中使用绝对路径引用图片")
while True:
choice = input("\n请输入选择 (1 或 2,默认为 1): ").strip()
if choice == "" or choice == "1":
IMAGE_STORE_MODE = "relative"
print("已选择:相对路径模式")
break
elif choice == "2":
IMAGE_STORE_MODE = "absolute"
print("已选择:绝对路径模式")
# 询问统一图片目录
default_dir = os.path.join(os.getcwd(), "imgs")
unified_dir = input(f"请输入统一图片存放目录(默认为 {default_dir}): ").strip()
if not unified_dir:
UNIFIED_IMAGE_DIR = default_dir
else:
UNIFIED_IMAGE_DIR = unified_dir
print(f"图片将统一保存到: {UNIFIED_IMAGE_DIR}")
break
else:
print("输入无效,请输入 1 或 2")
def main():
global SCAN_ROOT_DIR
# 交互式选择模式
select_mode()
# 用户输入指定目录
directory = input("\n请输入要扫描的目录路径: ").strip()
if not os.path.isdir(directory):
print("输入的路径不是有效的目录")
return
# 保存扫描根目录,用于绝对路径模式下保持目录结构
SCAN_ROOT_DIR = os.path.abspath(directory)
logging.info(f'============================= 日志分割线 =============================')
logging.info(f"图片存储模式: {IMAGE_STORE_MODE}")
if IMAGE_STORE_MODE == "absolute":
logging.info(f"统一图片目录: {UNIFIED_IMAGE_DIR}")
# 处理每个 Markdown 文件
md_files = read_all_file_list(directory)
success_files = 0
failed_files = []
failed_files_details = {}
file_stats = [] # 存储每个文件的统计信息
logging.info(f"Markdown 文件数量: {len(md_files)}")
for i, file_path in enumerate(md_files, 1):
logging.info(f"正在处理第{i}个文件: {file_path}")
is_success, failed_urls, success_count, failed_count = process_markdown_file(file_path)
# 记录文件统计信息
file_stats.append({
'file_path': file_path,
'success_count': success_count,
'failed_count': failed_count,
'is_success': is_success
})
if is_success:
success_files += 1
else:
failed_files.append(file_path)
failed_files_details[file_path] = failed_urls
# 新增:文件明细板块
logging.info(f'============================= 文件明细 =============================')
# 统计总体图片下载情况
total_success = sum(stat['success_count'] for stat in file_stats)
total_failed = sum(stat['failed_count'] for stat in file_stats)
logging.info(
f"总体统计: 总计处理文件数: {len(file_stats)}, 总成功图片数: {total_success}, 总失败图片数: {total_failed}")
logging.info(f"{'序号':<4} {'成功数':<6} {'失败数':<6} {'状态':<8} 文件路径")
logging.info(f"{'-' * 80}")
for idx, stat in enumerate(file_stats, 1):
status = "成功" if stat['is_success'] else "部分失败"
# 限制文件路径长度,避免日志过长(可选)
file_path_display = stat['file_path']
if len(file_path_display) > 60:
file_path_display = "..." + file_path_display[-57:]
logging.info(f"{idx:<4} {stat['success_count']:<6} {stat['failed_count']:<6} {status:<8} {file_path_display}")
logging.info(f"{'-' * 80}")
# 汇总日志
logging.info(f'============================= 汇总日志 =============================')
logging.info(f"全部成功文件数: {success_files}")
logging.info(f"有失败记录文件数: {len(failed_files)}")
if failed_files:
logging.warning("失败文件及其失败的 URL:")
for file_path in failed_files:
logging.warning(f" - 失败文件: {file_path}")
for url in failed_files_details[file_path]:
logging.warning(f" - 失败 URL: {url}")
# 删除无效目录(空目录)- 仅在相对路径模式下执行
if IMAGE_STORE_MODE == "relative":
remove_empty_dirs(directory)
else:
logging.info("绝对路径模式下跳过空目录清理")
if __name__ == "__main__":
# 初始化日志记录器
logging = get_logger()
start = time.time()
main()
end = time.time()
logging.info(f'共耗时: {round(end - start, 2)}秒')

